STACK
ทำความรู้จัก เครื่องมือใน Stack
ก่อนเข้า pipeline จริง — มาทำความเข้าใจ 4 องค์ประกอบหลัก ที่ทำงานร่วมกันเบื้องหลังระบบ AI ของเรา
01n8n
02Google Gemini · LLM
03LangChain Agent
04System Prompt
หลักสูตรอบรมเต็มวัน 6 พาร์ท — ตั้งแต่แนวคิดพื้นฐานของตัวชี้วัด การเก็บข้อมูล การคำนวณ การใช้ AI ไปจนถึงการสร้างแบบจำลองเชิงระบบ
ก่อนเข้าสู่การคำนวณและการเก็บข้อมูล — มาทำความเข้าใจ "ตัวชี้วัด" ว่าคืออะไร · ทำไมจึงต้องขยายให้ครอบคลุมหลายมิติ และ "กรอบแนวคิด" ที่ สศช. ใช้ในการพัฒนาตัวชี้วัดสำหรับเฝ้าระวังภาวะสังคม
ตัวชี้วัด คือ "ข้อมูลที่วัดได้อย่างเป็นระบบ" · ใช้สะท้อนสภาพ/การเปลี่ยนแปลงของสังคม · ติดตามต่อเนื่อง · เปรียบเทียบได้ในมิติเวลา–พื้นที่ — เพื่อ เฝ้าระวัง ก่อนปัญหาจะลุกลาม และเป็นหลักฐานเชิงประจักษ์ในการ ตัดสินใจเชิงนโยบาย
ปัจจุบันรายงานภาวะสังคมของ สศช. ครอบคลุม 6 ด้านที่มีข้อมูลรายไตรมาส ทำให้สามารถติดตามได้สม่ำเสมอ — แต่ยังไม่สะท้อนการเปลี่ยนแปลงในมิติอื่นที่มีนัยสำคัญต่อคุณภาพชีวิตของคนไทย เช่น สิ่งแวดล้อม · การศึกษา · ที่อยู่อาศัย · ครอบครัว
รายงาน 6 ด้าน ครอบคลุมเฉพาะข้อมูลที่หน่วยงานเก็บรายไตรมาสอย่างต่อเนื่อง — มิติเช่น สิ่งแวดล้อม · ที่อยู่อาศัย · ครอบครัว ยังไม่ได้ติดตามอย่างเป็นระบบ
OECD Better Life · UN SDR · Bertelsmann SGI · NZ Wellbeing ใช้มิติ 9–11 ด้าน ครอบคลุมทั้งสังคม–สิ่งแวดล้อม–การปกครอง — ไทยควรปรับให้สอดคล้อง
PM2.5 · ภัยแล้ง · ราคาที่อยู่อาศัย · สังคมสูงวัย · โครงสร้างครอบครัว — เป็นปัญหาที่ปะทุขึ้นใหม่และต้องการการเฝ้าระวังเชิงระบบ
จำกัดเฉพาะข้อมูลที่หน่วยงานรายงานเป็นรายไตรมาสอย่างต่อเนื่อง — ยังไม่ครอบคลุมการเปลี่ยนแปลงทางสังคมในมิติใหม่ที่กำลังเป็นประเด็น
ปรับ "หนี้สิน" → "การเงินครัวเรือน" ให้กว้างขึ้น · เพิ่ม 4 มิติใหม่ (สิ่งแวดล้อม · การศึกษา · ที่อยู่อาศัย · ครอบครัว) + คุณภาพชีวิตเป็นมิติรวม
งานจ้างที่ปรึกษามี 3 เป้าหมายหลัก — ศึกษากรอบ · รวบรวมข้อมูลและตัวชี้วัด · เสนอรูปแบบรายงานใหม่ · พร้อม ถ่ายทอดองค์ความรู้ผ่านการอบรม
ศึกษาและทบทวนมิติด้านสังคมและข้อมูลตัวชี้วัดที่ควรเสนอในรายงานภาวะสังคม สะท้อนสถานการณ์ปัจจุบัน
รวบรวมและจัดเก็บข้อมูลสถิติย้อนหลัง + จัดทำ "สารบัญข้อมูล" ด้านสังคมมิติต่าง ๆ ของประเทศไทย
ศึกษาและนำเสนอ "รูปแบบการจัดทำรายงานภาวะสังคม" — ทั้งโครงสร้าง · การนำเสนอ · การสื่อสารต่อผู้กำหนดนโยบาย
จัดอบรมการวิเคราะห์และจัดทำตัวชี้วัดให้กับเจ้าหน้าที่ สศช. ≥ 10 คน — (นี่คือสาระของหลักสูตรนี้!)
สศช. ใช้ "การยืนยันข้ามแหล่ง" (triangulation) ระหว่าง กรอบสากล × กรอบไทย × รายงาน สศช. เดิม — มิติที่ปรากฏซ้ำใน ≥ 2 แหล่ง จะถือว่ามีหลักฐานสนับสนุนเพียงพอที่จะเป็น "แกนกลาง" ของตัวชี้วัด
แต่ละแหล่งวิจัยมี "มิติของตัวเอง" — OECD เน้นคุณภาพชีวิต · UN SDR เน้นความยั่งยืน · Bertelsmann SGI เน้นธรรมาภิบาล · WEF เน้นความเสี่ยง · ไทยเน้นภาวะเศรษฐกิจ–สังคม — ถ้าเลือกแหล่งเดียวจะได้มุมที่จำกัด
สำรวจมิติของแต่ละแหล่ง แล้วใช้เกณฑ์ "ปรากฏซ้ำใน ≥ 2 แหล่ง" เป็นตัวกรอง — ยิ่งมิติหนึ่งปรากฏหลายแหล่ง ยิ่งมี หลักฐานเชิงประจักษ์ว่าเป็นมิติสำคัญต่อ "ภาวะสังคม"
ได้ 10 มิติแกนกลาง ที่ผ่านการยืนยันจากหลายแหล่ง · ทั้งสะท้อนคุณภาพชีวิตและภาวะสังคมไทยอย่างครอบคลุม · มีแหล่งข้อมูลที่ติดตามได้ในประเทศ
(1) ความสำคัญต่อภาวะสังคม · (2) มีข้อมูลในไทยที่ติดตามได้ · (3) วัดได้เป็นเชิงปริมาณ · (4) เปรียบเทียบข้ามเวลา/พื้นที่ได้
Part 02 จะลงลึก "แต่ละแหล่ง" — ดูว่า OECD BLI · UN SDR · SGI · NZ Wellbeing · Japan ใช้มิติอะไรบ้าง และไทยมีแหล่งข้อมูลอะไรรองรับ
สำรวจ กรอบสากล (OECD · SDR · SGI · WEF) · กรอบประเทศอื่น (นิวซีแลนด์ · ญี่ปุ่น) · รายงานในไทย (สศช. · พลังงาน · โทรคมนาคม) — สังเคราะห์เป็น "10 มิติแกนกลาง" พร้อมแหล่งข้อมูลที่นำมาใช้ได้จริง
แต่ละกรอบเน้น "มิติ" ต่างกัน — ตั้งแต่คุณภาพชีวิตประชากร · ความยั่งยืน · ธรรมาภิบาลภาครัฐ — รวมกันสะท้อนภาพรวมของ "ความเป็นอยู่"จากหลายมุมมอง
เผยแพร่โดย OECD · ใช้ข้อมูลจริงจากประเทศสมาชิก · ผู้ใช้สามารถถ่วงน้ำหนักมิติเองเพื่อสะท้อน "อะไรสำคัญกับฉัน" — เป็นกรอบที่มีอิทธิพลสูงสุดในการวัด wellbeing ระดับสากล
จัดทำโดย Sustainable Development Solutions Network · ใช้ข้อมูลจริงให้คะแนนความก้าวหน้าทั้ง 17 SDGs · ครอบคลุม 3 มิติ: เศรษฐกิจ · สังคม · สิ่งแวดล้อม + ธรรมาภิบาล
จัดทำโดย Bertelsmann Stiftung (เยอรมนี) · เน้นด้าน governance / institutional quality มากกว่ากรอบอื่น · ใช้ทั้งข้อมูลเชิงปริมาณ + ความเห็นผู้เชี่ยวชาญ
ตั้งแต่ Wellbeing Budget 2019 — ทุกนโยบายต้องตอบคำถาม "wellbeing impact"ก่อนได้รับงบ · กรอบมี 4 capitals ที่เป็นทุนระยะยาว: ธรรมชาติ · มนุษย์ · สังคม · การเงิน
ดูรายงานที่มีอยู่แล้วในไทย เพื่อเรียนรู้ "รูปแบบที่ใช้ได้จริง" และระบุ "ช่องว่าง" ที่งานนี้จะมาเติม — ทั้งด้านมิติที่ครอบคลุม · วิธีการคำนวณ · และวิธีนำเสนอ
สศช. เผยแพร่ "ภาวะสังคมไทย" รายไตรมาสมาตั้งแต่ปี 2546 ครอบคลุมเฉพาะข้อมูลที่หน่วยงานต่างๆ รายงานสม่ำเสมอ — เป็นข้อมูลที่ทุกฝ่ายอ้างอิงแต่ ขอบเขตเดิมจำกัดเฉพาะ "ข้อมูลที่มี"
สำนักงานนโยบายและแผนพลังงาน (สนพ.) เผยแพร่รายงานสถานการณ์พลังงานรายไตรมาส — ใช้ dashboard + time-series + trend analysis ให้ผู้อ่านเห็นภาพรวมได้รวดเร็ว · เป็นตัวอย่างที่ดีของการนำเสนอข้อมูลภาครัฐสมัยใหม่
สำนักงาน กสทช. เผยแพร่รายงานสถานการณ์โทรคมนาคมรายไตรมาส — เน้น tables · maps · ranking ของผู้ให้บริการที่ผู้บริหารใช้ตัดสินใจได้รวดเร็ว · มีโครงสร้างเปรียบเทียบตามเวลา · ภูมิภาค · บริการ
1) เพิ่ม 5 มิติใหม่ (สิ่งแวดล้อม · การศึกษา · ที่อยู่อาศัย · ครอบครัว · คุณภาพชีวิต) ที่รายงานเดิมไม่ครอบคลุม · 2) ใช้ Z-Score + Percentile แบบมาตรฐาน ทำให้เทียบกันได้ทั้งข้ามมิติและข้ามเวลา · 3) เสริม Social Listening + AI ติดตามกระแสรายวัน เติมช่องว่างของข้อมูลรายไตรมาส
จากการ "ยืนยันข้ามแหล่ง" (triangulation) ระหว่างกรอบสากล + ไทย + รายงานเดิม — ได้ 10 มิติแกนกลางที่ผ่านการตรวจสอบว่ามี ข้อมูลสนับสนุนในประเทศไทยและตอบโจทย์การเฝ้าระวังภาวะสังคม
| มิติ | แหล่งจริง | ตัวอย่างตัวแปร | ความถี่ | การเข้าถึง |
|---|---|---|---|---|
| แรงงาน | NSO (LFS) · ธปท. | การจ้างงาน · ว่างงาน · ค่าจ้างเฉลี่ย · แรงงานนอกระบบ | รายเดือน · รายปี | manual |
| การเงินครัวเรือน | NSO · ธปท. · NCB | หนี้ครัวเรือน · NPL · รายได้ครัวเรือน (SES) | รายไตรมาส · รายปี | manual |
| สุขภาพ | กรมสุขภาพจิต · กรมควบคุมโรค · สถาบันมะเร็ง | ผู้ป่วยซึมเศร้า · มะเร็ง · NCDs · โรคติดต่อ | รายปี | manual |
| ความปลอดภัย | สนง.ตำรวจฯ · มสป. · กองทุนเงินทดแทน | อาชญากรรมไซเบอร์ · อุบัติเหตุ · เสียชีวิตจากการทำงาน | รายเดือน · รายปี | manual |
| คุ้มครองผู้บริโภค | สคบ. · กสทช. · PDPC · กปว. | เรื่องร้องเรียน · ละเมิดข้อมูลส่วนบุคคล · scam | รายปี | manual |
| สิ่งแวดล้อม | OpenAQ · Open-Meteo · DDPM · กรมควบคุมมลพิษ | PM2.5 รายวัน · ฝนรายวัน · ภัยพิบัติ | รายวัน · รายเดือน · รายปี | API + manual |
| การศึกษา | สป.อว. · ศธ. · สพฐ. | อัตราเข้าเรียน · ผู้สำเร็จการศึกษา · NEET | รายปี | manual |
| ที่อยู่อาศัย | ธปท. | ดัชนีราคาที่อยู่อาศัย · housing affordability | รายไตรมาส | manual |
| ครอบครัว | VCIS (ศูนย์ปฏิบัติการป้องกันความรุนแรงในครอบครัว) | เคสความรุนแรง · เด็กที่ถูกทอดทิ้ง · คดีหย่า | รายปี | manual |
import requests # 1) หาสถานี PM2.5 ในไทย (parameters_id=2 คือ PM2.5) locs = requests.get( "https://api.openaq.org/v3/locations", headers={"X-API-Key": OPENAQ_KEY}, params={"iso": "TH", "parameters_id": 2}, ).json()["results"] # 2) ดึงค่ารายวัน 1 ปี ของแต่ละสถานี for loc in locs: sid = loc["sensors"][0]["id"] daily = requests.get( f"https://api.openaq.org/v3/sensors/{sid}/days", params={"date_from": "2024-01-01", "date_to": "2024-12-31"}, ).json()["results"]
import requests # Open-Meteo Archive — ไม่ต้องใช้ API key # ตัวอย่าง: จังหวัดนครศรีธรรมราช (8.9°N, 99.0°E) r = requests.get( "https://archive-api.open-meteo.com/v1/archive", params={ "latitude": 8.9034, "longitude": 99.0129, "start_date": "2020-01-01", "end_date": "2024-12-31", "daily": "rain_sum", "timezone": "Asia/Bangkok", }, ).json() dates = r["daily"]["time"] rain = r["daily"]["rain_sum"]
ทุกตัวชี้วัด สศช. ผ่าน pipeline เดียวกัน — ทำความสะอาด รวบรวม ปรับมาตรฐานด้วย Z-Score แล้วตีความเป็น 4 สีระดับวิกฤต
ขั้นที่ 1-2 · เปลี่ยนข้อมูลดิบรายไตรมาสให้เป็นอัตราเติบโตปีต่อปี (%YoY)
| ไตรมาส | ค่าจ้าง | %YoY |
|---|---|---|
| Q1/2562 | 14,557 | +1.40% |
| Q2/2562 | 14,809 | +3.54% |
| Q3/2562 | 14,770 | +1.42% |
| Q4/2562 | 14,694 | +0.95% |
| Q1/2563 | 14,876 | +2.19% |
| Q2/2563 | 14,820 | +0.07% |
| Q3/2563 | 15,148 | +2.56% |
| Q4/2563 | 15,113 | +2.85% |
| Q1/2564 | 14,386 | −3.29% |
เปลี่ยน "ค่าดิบ" ที่มีฤดูกาลปะปน ให้เป็น "อัตราการเติบโต" ที่สะท้อนการเปลี่ยนแปลงจริงระหว่างปี — เป็นรูปแบบที่ขั้น Z-Score ต้องการ (ตัวเลข %change ที่เปรียบเทียบกันได้)
เทียบ Vt กับ Vt−4 ซึ่งเป็น ไตรมาสเดียวกันของปีก่อน (Q1 เทียบ Q1) บริบทฤดูกาลคล้ายกัน → เมื่อหารกัน ผลฤดูกาลหักล้าง เหลือเฉพาะการเปลี่ยนแปลงระหว่างปี
ขั้นที่ 3a · สร้าง "ค่ามาตรฐาน" จากช่วงอ้างอิง 8 ไตรมาสล่าสุด
ผลรวมของค่าทั้งหมดในช่วงอ้างอิง หารด้วยจำนวนข้อมูล — บอก "ระดับปกติ" ของตัวชี้วัด
เป็น "จุดศูนย์กลาง" ของ Z-Score — ค่าใหม่สูงกว่า μ ได้ Z บวก, ต่ำกว่า μ ได้ Z ลบ
วัดว่าข้อมูลกระจายห่างจากค่าเฉลี่ยมากน้อยเพียงใด — σ สูง = ผันผวน, σ ต่ำ = เสถียร
เป็น "หน่วยวัดระยะ" ใน Z-Score — แยกความผันผวนทั่วไปออกจากสัญญาณผิดปกติ
เพราะใช้ข้อมูลครบทั้ง 8 ไตรมาสล่าสุด เป็น "ประชากรของช่วงอ้างอิง" โดยตรง ไม่ได้สุ่มเป็นตัวแทน — จึงหารด้วย N ไม่ใช่ N−1 แบบ Sample SD
ขั้นที่ 3b · แปลงค่าเป็น "หน่วยมาตรฐาน" เพื่อเทียบข้ามตัวชี้วัดได้
Z = +1 สูงกว่าค่าเฉลี่ย 1 SD
Z = −2 ต่ำกว่าค่าเฉลี่ย 2 SD
คำว่า "ค่าสูง" ของแต่ละตัวชี้วัดมีความหมายไม่เหมือนกัน — เราจึงต้องปรับให้ทุกตัวพูดภาษาเดียวกัน
higherIsBetter = true →
Zadj = −(−4.91) =
+4.91
ขั้นที่ 3c · แปลง Z-Score เป็น Percentile และระดับสัญญาณ
Percentile = 80 สูงกว่า 80% ของค่าในอดีต
Percentile = 20 ค่อนข้างต่ำเมื่อเทียบกับอดีต
ทุกขั้นจากสไลด์ 3.2 – 3.5 ถูกประมวลผลอัตโนมัติในระบบ NESDC Social Pulse
/zscore เป็น "sandbox ทดลองคำนวณ" — ผู้ใช้สลับได้ทั้ง วิธีที่ 1 (ค่าตรง) และ วิธีที่ 2 (%QoQ / %YoY) เพื่อเทียบผลลัพธ์ — ระบบแสดง ค่าล่าสุด, Z-Score, Percentile และสัญญาณสีพร้อมกัน
/dimensions/*, /monthly) ใช้ วิธีที่ 2 (%QoQ/%YoY) เป็นหลักเสมอ เพราะตัดผลฤดูกาลออก เหมาะกับการเฝ้าระวัง
ตัวชี้วัด: จำนวนวันที่ PM2.5 ≤ 25 µg/m³ ต่อไตรมาส (วันอากาศดี) · ทิศทาง: สูง = ดี (positive) · ข้อมูล 8 ไตรมาสย้อนหลัง 2 ปี — ลองทายว่าค่าปัจจุบันเข้าโซนสัญญาณไหน
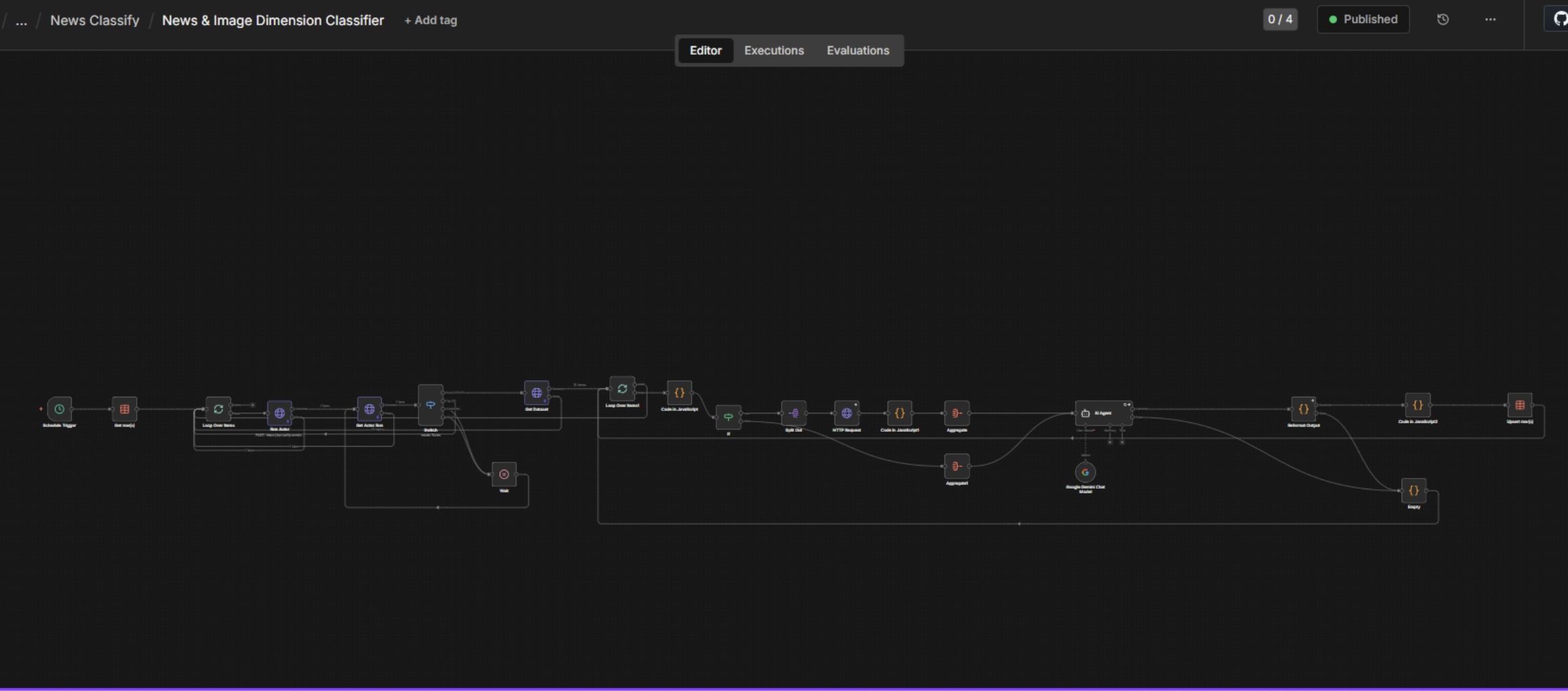
ระบบ NESDC Social Pulse ใช้ AI อัตโนมัติทั้ง pipeline — ตั้งแต่ดูดข่าว จัดมิติด้วย Vision AI สรุปเป็น digest ด้วย LLM Agent และส่งออกผ่าน Dashboard, Google Drive และรายงานเชิงนโยบาย
ก่อนเข้า pipeline จริง — มาทำความเข้าใจ 4 องค์ประกอบหลัก ที่ทำงานร่วมกันเบื้องหลังระบบ AI ของเรา
"เครื่องมือต่อ workflow แบบ drag-and-drop" — ลากกล่องงานเชื่อมเป็น flow แล้วระบบรันเองอัตโนมัติ
Open-source workflow automation — เปิดให้ทำงานต่อ ๆ กันโดยไม่ต้องเขียนโค้ดเอง ใช้ "node" (กล่อง) แทนแต่ละขั้นตอน ลากเชื่อมกันเป็น flow บนหน้าจอ
Schedule Trigger → HTTP Request → AI Agent → Upload to Drive — ทุก node ส่งข้อมูลให้ node ถัดไป รันตามที่ตั้ง cron ไว้
Zapier หรือ Make.com — แต่ self-hosted (เก็บข้อมูลในเซิร์ฟเวอร์ของเรา) + open-source (ไม่ต้องจ่ายรายเดือน)
ระบบเราใช้ n8n orchestrate ทั้ง pipeline — ดึงข่าว, ส่งให้ Gemini, รับผลลัพธ์, เขียนกลับ Data Table, ส่งขึ้น Drive
"AI ที่อ่านข้อความและดูรูปได้ในตัวเดียวกัน" — เหมาะกับการจัดมิติข่าวที่มีทั้งหัวข้อ + เนื้อหา + รูปประกอบ
Large Language Model ของ Google — AI ที่ฝึกจากข้อความและภาพมหาศาล ตอบกลับเป็นภาษาธรรมชาติได้หลายภาษารวมถึงไทย
ทำงานทั้ง ข้อความ + ภาพ + เสียง ใน model เดียว — ไม่ต้องแยกใช้ Vision API กับ Text API คนละตัว
ChatGPT หรือ Claude — แต่ Gemini จาก Google เน้น multimodal + ผูกกับ Google Cloud + ราคาคุ้ม
ระบบใช้ Gemini เป็น "สมอง" ของทุก AI Agent — จัดมิติข่าว, สรุปบทความ, วิเคราะห์ trend
"type": "แรงงาน","confidence": 0.94,"reasoning": "เห็นป้ายค่าจ้าง + กลุ่มผู้ชุมนุม""ห่อ LLM ให้ทำงานคงเส้นคงวา" — รวม system prompt + LLM + memory + tools เข้าด้วยกันเป็น "พนักงาน" หนึ่งคน
Framework ที่ใส่ "บทบาท + กฎ + เครื่องมือ" ให้ LLM — ทำให้ AI ตอบคงเส้นคงวา + format ตามที่ต้องการ + เรียกใช้ tool เพิ่มเติมได้
System Prompt (บทบาท/กฎ) + LLM (สมอง) + Memory (ความจำในรอบสนทนา) + Tools (ดึงข้อมูล/API)
"พนักงาน + job description + เครื่องมือทำงาน" — ไม่ใช่แค่คนเก่ง แต่ทำงานตามขั้นตอนและส่งงานในฟอร์แมตเดียวกันทุกครั้ง
ระบบเรามี 3 Agent: Chunk Analyzer (สรุปข่าวก้อนเล็ก), Merger (รวมเป็นบทความ), Weekly Pulse (วิเคราะห์เส้นเรื่องสัปดาห์)
"คำสั่งและกฎ" ที่ AI อ่านทุกครั้งก่อนเริ่มงาน — กำหนดบทบาท ขั้นตอนคิด รูปแบบผลลัพธ์ และข้อห้าม
ข้อความล่วงหน้า ที่ฝังในตัว Agent — บอก AI ว่าเป็นใคร ทำอะไร ตอบยังไง และห้ามทำอะไร — เขียนครั้งเดียว ใช้ตลอดอายุของ Agent
ROLE (เป็นใคร) + INSTRUCTIONS (ทำอะไร) + OUTPUT FORMAT (ตอบหน้าตาแบบไหน) + GUARDRAILS (ห้ามอะไร)
SOP / คู่มือทำงาน ที่พนักงานต้องอ่าน ทุกครั้งก่อนทำงาน — รับประกัน "คุณภาพ + ความคงเส้นคงวา" ไม่ขึ้นกับวันไหน
NO HALLUCINATION — กฎห้าม AI "แต่งข้อมูล" ที่ไม่มีในอินพุต ป้องกัน AI พูดมั่ว ๆ ที่อันตรายต่อรายงานนโยบาย
ทุกเช้า 07:00 ระบบรันเอง — 5 ขั้นเรียงกันทำงานต่อเนื่อง ใน 7 นาที จนได้ ราว 300 rows พร้อมส่งให้ AI วิเคราะห์
ขั้นที่ 01 · ใช้ cron ตั้งเวลาให้ workflow รันทุกเช้า — ไม่ต้องมีคนกดเอง
0 7 * * * = "นาที 0 ของชั่วโมง 7 ทุกวัน" — ทำหน้าที่เหมือน "นาฬิกาปลุก" ของระบบ
Schedule Trigger เป็น background service — ทุกครั้งที่ถึงเวลาที่ตั้ง จะ "ปลุก" workflow ให้รันตั้งแต่ node แรกจนจบ
{ "triggered_at": "2026-05-17T07:00:00+07:00" } ให้ node ถัดไป (RSS Fetch)
ขั้นที่ 02 · เรียกอ่านข่าวจากเว็บข่าวประมาณ 50 แห่งพร้อมกัน ส่วนใหญ่ผ่าน RSS feed
HTTP Request ยิงหา feed URL ทุกแหล่งคู่ขนาน → ได้ XML/HTML กลับ → node Code in JavaScript parse เอาเฉพาะ title · link · pubDate · summary
ขั้นที่ 03 · เก็บโพสต์สาธารณะที่มี รูปประกอบ พร้อมตัวเลข likes/comments/shares
postURL, imageURL, caption, likes, comments, shares
ขั้นที่ 04 · เรียก API ของ สสช, ธปท, ฯลฯ เพื่อนำตัวเลขจริงมาเทียบกับกระแสในข่าว
HTTP Request ยิง GET หา endpoint ของแต่ละหน่วยงาน → ได้ JSON/CSV → parse เป็นแถวข้อมูล (เช่น อัตราว่างงาน · CPI · PM2.5)
ขั้นที่ 05 · เขียนทุกแถวเข้าตาราง n8n schema เดียวกัน — พร้อมส่งต่อให้ CLASSIFY
Insert row เขียนทุก record จาก 3 แหล่งก่อนหน้าเป็นแถว — ใช้ schema เดียวกัน: id · source · time · type · payload · metrics
| time | source | type | preview |
|---|---|---|---|
| 07:01 | thairath.co.th | news | "ค่าจ้างขั้นต่ำ 400 บาท..." |
| 07:01 | matichon.co.th | news | "หนี้ครัวเรือนทรงตัว..." |
| 07:03 | fb/ThaiPBSNews | social | 👍 1,240 · "ค่าจ้าง 400..." |
| 07:03 | fb/DiseaseDept | social | 👍 720 · "เตือนหวัดใหญ่..." |
| 07:05 | api.nso.go.th | stats | unemployment Q1 = 1.18 |
ข้อมูล 300 rows เข้า Data Table แล้ว — ตอนนี้ AI Agent รับช่วงต่อ จัดมิติ · สรุปเป็น digest · ส่งออกผ่าน 3 ช่องทาง
ขั้นที่ 02 · ใช้ Google Gemini (multimodal AI) อ่านทั้งข้อความและรูปประกอบ แล้วระบุว่าข่าวเข้ามิติไหนของภาวะสังคม สศช.
ข่าว 1 ชิ้นประกอบด้วย หัวข่าว · เนื้อข่าวสรุป · URL รูปประกอบ — AI อ่านทั้ง 3 อย่าง พร้อมกัน ไม่ใช่แค่จับคู่ keyword
"Vision" = ดูรูปเข้าใจเนื้อหาเหมือนคนดู (เห็นคน/สถานที่/อารมณ์) · "LLM" = อ่านข้อความเข้าใจบริบทและนัยยะ — Gemini ทำ ทั้ง 2 อย่างใน model เดียว เทียบกับ นิยาม 10 มิติ ที่อยู่ใน system prompt
ส่งคืน JSON: type = ชื่อมิติ · confidence = ความมั่นใจ (0–1) · reasoning = ทำไมเลือกมิตินี้ — ทุกค่า บันทึกกลับ Data Table เพื่อให้ขั้นถัดไปใช้ต่อ
จัดข่าวเข้า 10 มิติของ สศช. · ทดลอง 8 ข่าวจริงที่ AI Agent ของเราเคย classify
ขั้นที่ 03 · ให้ Google Gemini "เขียน" บทความสรุปข่าวเองอัตโนมัติ — แทนคนที่ต้องนั่งอ่านข่าวทั้งวันแล้วเขียนสรุป
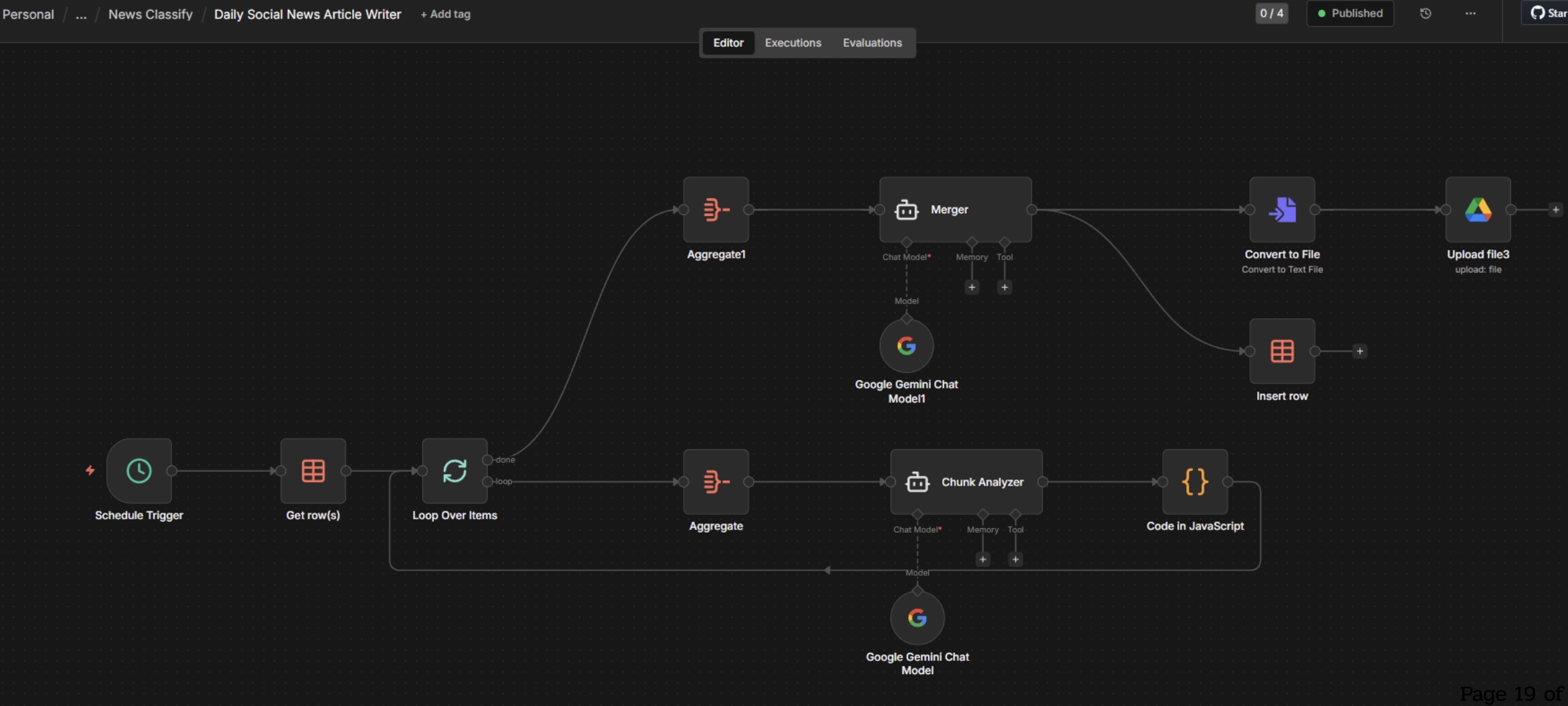
ข่าว 1 วันมีเยอะมาก (100–500 ชิ้น) — ถ้าส่งทั้งหมดให้ Agent ครั้งเดียวจะเกินขีดจำกัด (context window) เราจึงแบ่งเป็น "ก้อนเล็ก ๆ" (chunks) ให้ Chunk Analyzer สรุปทีละก้อน แล้วส่งสรุปย่อยทั้งหมดให้ Merger รวมเป็นบทความเดียว
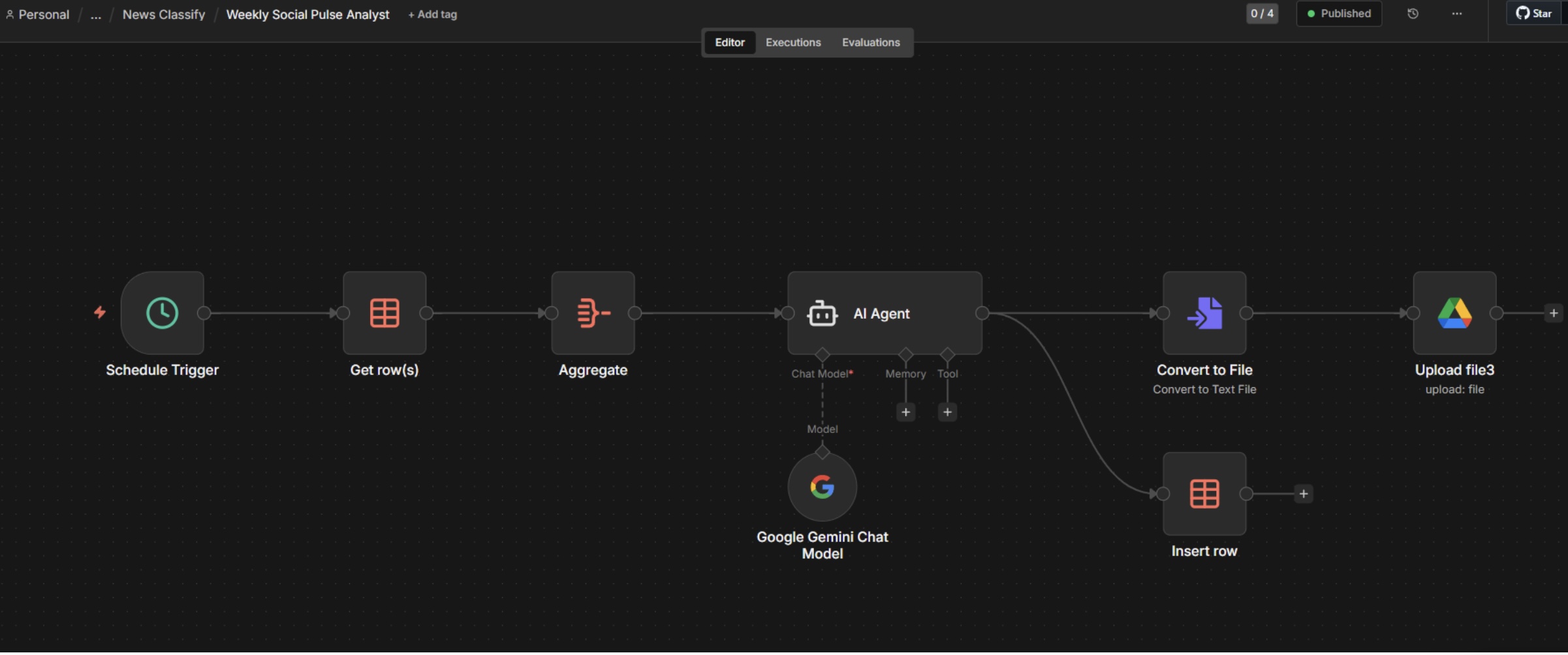
รายสัปดาห์อินพุตน้อยกว่า — แค่ digest 7 วัน (ที่ AI สรุปย่อให้แล้ว) ใส่ครั้งเดียวให้ Agent ตัวเดียว วิเคราะห์ "Story Clustering" เพื่อรวมเรื่องเดียวกันข้ามวัน + จับ "เส้นเรื่อง เริ่ม-พีก-แผ่ว" ของสัปดาห์
ขั้นที่ 04 · AI digest "กระจาย" ไปยัง 3 ช่องทางพร้อมกัน ตามบทบาทผู้ใช้
ใช้ตอน: เช้านี้เปิดอ่านดูข่าวเมื่อวาน · มี factual error ก็ comment + edit เก็บเป็น feedback ปรับ prompt
ใช้ตอน: ประชุมเช้าจันทร์ · ดูข่าวเด่น + Z-Score ในที่เดียว → ตัดสินใจในห้องประชุมทันที
ใช้ตอน: AI ให้ "ฉบับร่าง" · ทีมขัดเกลา + ตรวจสอบข้อเท็จจริง → เผยแพร่ รายไตรมาส/ปี
มี 5 บล็อกใน palette — ลากลง "ช่อง pipeline" ให้ถูกลำดับการทำงาน (trigger → ingest → process → format → publish)
ไม่ใช่แค่ "ฟัง" โซเชียลแบบเรียลไทม์ แต่ จัดมิติ · คำนวณ trendScore · คลัสเตอร์เรื่องราว ข้ามวัน แล้วสรุปเป็น digest รายสัปดาห์ที่ใช้ประกอบการตัดสินใจเชิงนโยบายได้
Pulse รายสัปดาห์ "ไม่ได้สร้างจากศูนย์" — แต่ สังเคราะห์ จาก digest 7 วันที่ผ่านมา ด้วย Story Clustering
ทุกเย็น AI สร้างรายงานสรุปข่าวเป็น Markdown เก็บใน Google Drive — เป็น "วัตถุดิบ" ของ Weekly Pulse
ไฟล์ Markdown ชื่อ daily-YYYY-MM-DD.md ที่ AI Agent "Daily Social News Article Writer" สร้างขึ้นทุกวัน — เก็บใน Google Drive
TL;DR · Topic Radar 10 มิติ · ประเด็นเด่นของวัน · Top Posts เรียง trendScore · Watchlist
"หนังสือพิมพ์รายวัน" ของ social media — มี headline ของวัน · 10 หมวด · เรื่องเด่นพร้อมลิงก์
เป็น "input" ที่ Weekly Pulse Analyst อ่าน 7 ฉบับเพื่อสังเคราะห์เป็นรายงานสัปดาห์
ทุกวันจันทร์เช้า AI Agent อ่าน digest 7 วัน ที่ผ่านมา แล้วเขียน "รายงานกระแสโซเชียลประจำสัปดาห์"
LangChain Agent ที่มี role ชัดเจน + Google Gemini เป็นสมอง — รับ input markdown 7 ฉบับ ส่งคืน 1 รายงานสัปดาห์
หาว่าเรื่องไหน "ลากยาว" · เรื่องไหน "พุ่งเป็นวัน ๆ" · มี "เส้นเรื่อง" อะไรบ้าง · จัดอันดับ Watchlist ของสัปดาห์
"บรรณาธิการสัปดาห์" ที่อ่านหนังสือพิมพ์ 7 ฉบับ แล้วเขียน "editorial" สรุปประเด็นเด่น
NO HALLUCINATION · ห้ามอ้างแหล่งอื่นนอก daily · ภาษากลาง "ไม่ปลุกปั่น"
เทคนิคที่ AI ใช้ลดข่าวซ้ำ + เห็นว่า "เรื่องเดียวกันมีจุดเริ่ม-พีก-แผ่ว" ตอนไหน
เรื่องเดียวกันกระจายอยู่ในหลาย daily — เช่น "ค่าจ้าง 400" ปรากฏใน 5 วัน ถ้านำเสนอแยกเป็น 5 ข่าวจะ "ซ้ำซาก" และเห็นภาพไม่ครบ
AI จับคู่ "คีย์เวิร์ดร่วม" + "บุคคล/สถานที่/มาตรการ" ของแต่ละ daily — ตั้งชื่อ storyline เดียวกัน
"เส้นเรื่องสัปดาห์" ที่เล่าได้ว่า: เริ่มวันไหน · พีกเมื่อใด · แผ่วเมื่อไหร่ · มีปริมาณรวมเท่าไหร่
AI Agent ระบุว่าแต่ละโพสต์เข้ามิติไหน แล้วรวมเป็น trendScore ต่อมิติ ต่อวัน
AI Agent ส่งคืนเป็น Markdown ตาม template — มีหัวข้อแน่นอน อ่านง่าย + อ้างอิงลิงก์หลักฐานทุกประเด็น
| มิติ | โพสต์ | trendScore | % |
|---|---|---|---|
| แรงงาน | 348 | 12,480 | 27.1% |
| สุขภาพ | 302 | 10,950 | 23.8% |
| การเงินครัวเรือน | 198 | 7,210 | 15.7% |
| ความปลอดภัย | 156 | 5,640 | 12.3% |
รวม "เรื่องเดียวกัน" ข้ามวัน + จัดอันดับประเด็น "ควรตรวจสอบต่อ" ด้วย ความถี่ × ความอ่อนไหว
Agent ห้ามแต่งข้อมูล — อ้างเฉพาะ daily digest + ทุก storyline มีลิงก์หลักฐาน
เปิด /pulse ปุ๊บ เห็น Topic Radar + เรื่องเด่นรายวัน + storyline พร้อมหลักฐานทันที
หน้า /weekly เก็บ Weekly Social Pulse Report ทุกฉบับ — คลิกเข้าฉบับใดเพื่อดูรายงานเต็มที่ AI Agent เขียน
เลื่อน slider ปรับ likes / comments / shares · ดูสูตร = likes + 2×comments + 3×shares ทำงานสด ๆ
ทำไมนโยบายที่ดูเหมือนสมเหตุสมผลถึง "ล้มเหลว"? — เพราะระบบมี "feedback loops" ที่มองไม่เห็น · System Dynamics คือเครื่องมือที่ช่วย มองเห็นโครงสร้าง แล้วเข้าใจว่าทำไมระบบ "ตอบสนอง" แบบนั้น
ทำ System Dynamics ได้ตั้งแต่ "ดินสอ + กระดาษ" ไปจนถึง software simulator เต็มรูปแบบ — เลือกตามความซับซ้อนของโจทย์
เครื่องมือพื้นฐานสำหรับ "คิดบนกระดาน" — เริ่มจาก stocks, flows, arrows ก่อนใส่ตัวเลข
Software มาตรฐาน ในวงการ SD — มี Personal Edition ให้นักศึกษาใช้ฟรี · ใช้กับงานวิจัย/นโยบายเชิงลึก
SD บน browser — ใช้ฟรีไม่ต้องลง สร้างโมเดลแล้วแชร์ URL ให้ทีมดูได้ทันที เหมาะกับการสอน
สำหรับ โมเดลง่ายๆ หรือ integration กับข้อมูล — Excel ทำ Euler integration ได้ · Python (PySD) แปลง model file ได้
เพราะ "Mental Model" ในหัวเรา ไม่ใช่ความจริง — เป็นการตีความส่วนตัวที่อาจผิดได้
บังคับให้เราระบุ ตัวแปร · ความสัมพันธ์ · ทิศทาง สิ่งที่ "เห็น" บ่อยครั้งไม่ใช่สิ่งที่ "เป็น"
ทีมหลายฝ่ายมี mental model ต่างกัน — model เป็น "ภาษากลาง" ที่ทุกคนเห็นและถกได้
ลองนโยบายใน model "ก่อนใช้จริง" ป้องกัน unintended consequences ที่อาจเสียงบมหาศาล
หา "จุดคันโยก" ที่เปลี่ยนระบบได้มากที่สุด — แทนการแก้ที่ปลายเหตุ
มี model หลายประเภท — แต่ละแบบเหมาะกับโจทย์ต่างกัน · เราเลือก System Dynamics เพราะ "จับ feedback loops ได้"
รูปภาพ · แผนผัง · กราฟ — สื่อความคิดเร็ว แต่ไม่ คำนวณ ได้
สมการฟิสิกส์/เคมี F=ma · E=mc² — แม่นยำแต่ใช้กับระบบสังคมยาก
หา "ความสัมพันธ์" จากข้อมูล — บอก correlation ไม่ใช่ causation
จำลองเหตุการณ์แยกชิ้น เช่น คิวธนาคาร · เครื่องบินขึ้น-ลง
จำลอง หน่วยย่อยหลายตัวที่มีกฎของตัวเอง — เช่น คน · บริษัท · เซลล์
จับ "การไหลของ stock" + "feedback loops" — เหมาะกับ นโยบายเชิงระบบ
ก่อนสร้าง model ต้อง "คิดเชิงระบบ" — ฝึก 8 ทักษะนี้ ใช้ได้ทุกวันแม้ไม่สร้าง model
มองที่ โครงสร้าง เป็นเหตุ ไม่โทษคน/เหตุการณ์เดี่ยว
ระบบ เปลี่ยนตามเวลา ไม่ใช่ snapshot · ดู trend + oscillation
สลับ zoom-out / zoom-in เห็นทั้งภาพรวมและรายละเอียด
ทุกตัวแปร วัดได้ + มี units ชัดเจน · ไม่ใช้คำกว้างๆ
ทุก output ย้อนกลับ มีผลต่อ input — feedback loops
เพิ่ม input 2 เท่า ไม่ได้ทำให้ output โต 2 เท่า · มี threshold
ตั้ง สมมติฐาน + ทดสอบ + ยอมรับว่าผิดแล้วแก้
มองมุมของ stakeholders ทุกฝ่ายในระบบ · ไม่ใช่แค่มุมเรา
Stock คือสิ่งที่ "นับได้ ณ จุดเวลาหนึ่ง" — เป็น คำนาม เสมอ · เช่น น้ำในอ่าง · เงินในบัญชี · ประชากร
"การสะสม" (accumulation) ของบางสิ่ง ณ ช่วงเวลาหนึ่ง — ถ้าหยุดเวลาแล้วถ่ายรูป จะ วัดได้
Stock ต้องเป็น "คำนาม" เท่านั้น — ไม่ใช่ verb · ไม่ใช่ adjective · ไม่ใช่ adverb
"น้ำในอ่างอาบน้ำ" — ระดับน้ำ ณ เวลาที่มอง บอกได้ว่ามีเท่าไหร่ · เปลี่ยนแปลงช้าๆตามการไหลเข้า-ออก
หน่วยของ stock ไม่มี "เวลา" — เช่น คน · บาท · ลิตร · kg
| STOCK | หน่วย | นิยาม |
|---|---|---|
| ประชากร | คน | คนที่อาศัยอยู่ ณ เวลาหนึ่ง |
| หนี้ครัวเรือน | ล้านบาท | เงินกู้ที่ยังคงค้างของครัวเรือนทั้งหมด |
| PM2.5 ในอากาศ | μg/m³ | ปริมาณฝุ่น ณ จุดวัด ณ เวลาหนึ่ง |
| ผู้ป่วย NCDs | คน | คนป่วยโรคไม่ติดต่อ ณ เวลาหนึ่ง |
| ความรู้ | หน่วยความรู้ | knowledge สะสมในตัวคน/องค์กร |
| ความไว้ใจ | หน่วย trust | ความเชื่อถือสะสมระหว่างหน่วยงาน |
ระดับเปลี่ยนตามเวลา (stock = accumulation) · แต่ หยุดเวลาเมื่อไหร่ก็วัดได้ทันที — ค่าตายตัว ณ จุดนั้น
Flow คือสิ่งที่ "เปลี่ยน stock" ในแต่ละช่วงเวลา — เป็น คำกริยา เสมอ + ต้องมีหน่วย /เวลา
"อัตรา" (rate) ของการเข้า/ออกของ stock — ถ้าหยุดเวลา flow จะ "หายไป" ทันที (เพราะไม่มีเวลา)
Flow ต้องเป็น "คำกริยา" เสมอ + มีหน่วย /เวลา เช่น คน/ปี · บาท/เดือน
"ก๊อกน้ำ" (inflow) + "ท่อระบาย" (outflow) ของอ่างอาบน้ำ · ระดับน้ำเปลี่ยนตาม flow ทั้งสอง
Flow มี "/เวลา" เสมอ — debug model ด้วยการตรวจ หน่วย stock = หน่วย flow × เวลา
| FLOW | หน่วย | เปลี่ยน stock |
|---|---|---|
| อัตราเกิด | คน/ปี | ↑ ประชากร |
| อัตราตาย | คน/ปี | ↓ ประชากร |
| กู้เพิ่ม | ล้านบาท/เดือน | ↑ หนี้ครัวเรือน |
| คืนหนี้ | ล้านบาท/เดือน | ↓ หนี้ครัวเรือน |
| การปล่อยฝุ่น | μg/m³ ต่อชั่วโมง | ↑ PM2.5 |
| ลมพัดฝุ่นออก | μg/m³ ต่อชั่วโมง | ↓ PM2.5 |
flow มี "อัตรา" (เช่น +5 คน/ปี) — แต่ละหยดที่ไหลผ่านวาล์ว เพิ่ม stock ทีละนิด · ถ้าหยุดเวลา flow จะ "หายไป" เพราะไม่มีเวลา
เลื่อน slider ปรับอัตราเข้า/ออก · ระบบรัน 10 วัน ต่อรอบ แสดงระดับน้ำในอ่าง + กราฟ stock ตามเวลา
In > Out → โต · In < Out → หด · เท่า → คงที่
กฎจำง่าย: Stock = นาม วัดได้ ณ จุดเวลาหนึ่ง · Flow = กริยา + มีหน่วย /เวลา
ทุกตัวแปรใน model ต้องมี "หน่วย" — ใช้ debug model ได้อย่างน่าทึ่ง · ถ้าหน่วยไม่ตรง = สมการผิด
คน = คน/ปี + บาท แสดงว่ามีบางอย่างผิดทันที (หน่วยไม่ตรงกัน)
คน · บาท · ลิตร · °C — ไม่มี "เวลา" อยู่ในหน่วย
คน/ปี · บาท/เดือน · ลิตร/นาที — มี "/เวลา" เสมอ
ตัวแปรช่วย เช่น % · ratio · dimensionless — ใช้คำนวณตัวอื่น
ทุกสมการต้อง "หน่วยลงตัว" ทั้ง 2 ข้าง · ถ้าไม่ตรง = ผิดแน่นอน
BOTG = วาดกราฟ "พฤติกรรมของ stock" ตามเวลา — ใช้เป็น reference mode ที่ model ต้องสามารถ reproduce ได้ · วาด BOTG ก่อนสร้าง model เสมอ เพื่อใช้เป็นเข็มทิศ
กราฟง่ายๆ ที่มี เวลาเป็นแกน X และ ค่าของ stockเป็นแกน Y · ใช้สื่อ "พฤติกรรมที่ต้องการอธิบาย"
"กราฟอ้างอิง" ที่บอกว่าระบบ เคยทำตัวอย่างไร + คาดว่าจะทำต่ออย่างไร · model ต้อง reproduce ได้
4 แบบที่พบบ่อย: linear · exponential · S-curve · oscillation — แต่ละแบบมี structural causeต่างกัน
CLD = แผนภาพแสดง feedback loops · มี 2 ชนิด — R (เร่ง) · B (สมดุล) — ทุกระบบประกอบจากการรวมกันของ 2 ชนิดนี้
"snowball" — ทุกตัวแปร เพิ่มตัวต่อไปในทิศทางเดียว → ระบบโตหรือพังเร็วขึ้น
"thermostat" — มีตัวแปรหนึ่ง ลดตัวต่อไป → ระบบเข้าหา เป้าหรือ สมดุล
3 ขั้น: เลือกตัวแปร → เชื่อมลูกศร + ขั้ว → ระบุ R หรือ B
เลือก 3 ตัวแปร ที่เป็น "ส่วนหนึ่งของ feedback loop" ในปัญหาหนี้ครัวเรือน
คลิก "จุดกลางลูกศร" เพื่อเลือกขั้ว — + (ไปทางเดียวกัน) หรือ – (ไปทางตรงข้าม)
loop ที่ได้คือ Reinforcing (R) หรือ Balancing (B)?